MM Algorithm Principles
Duke University
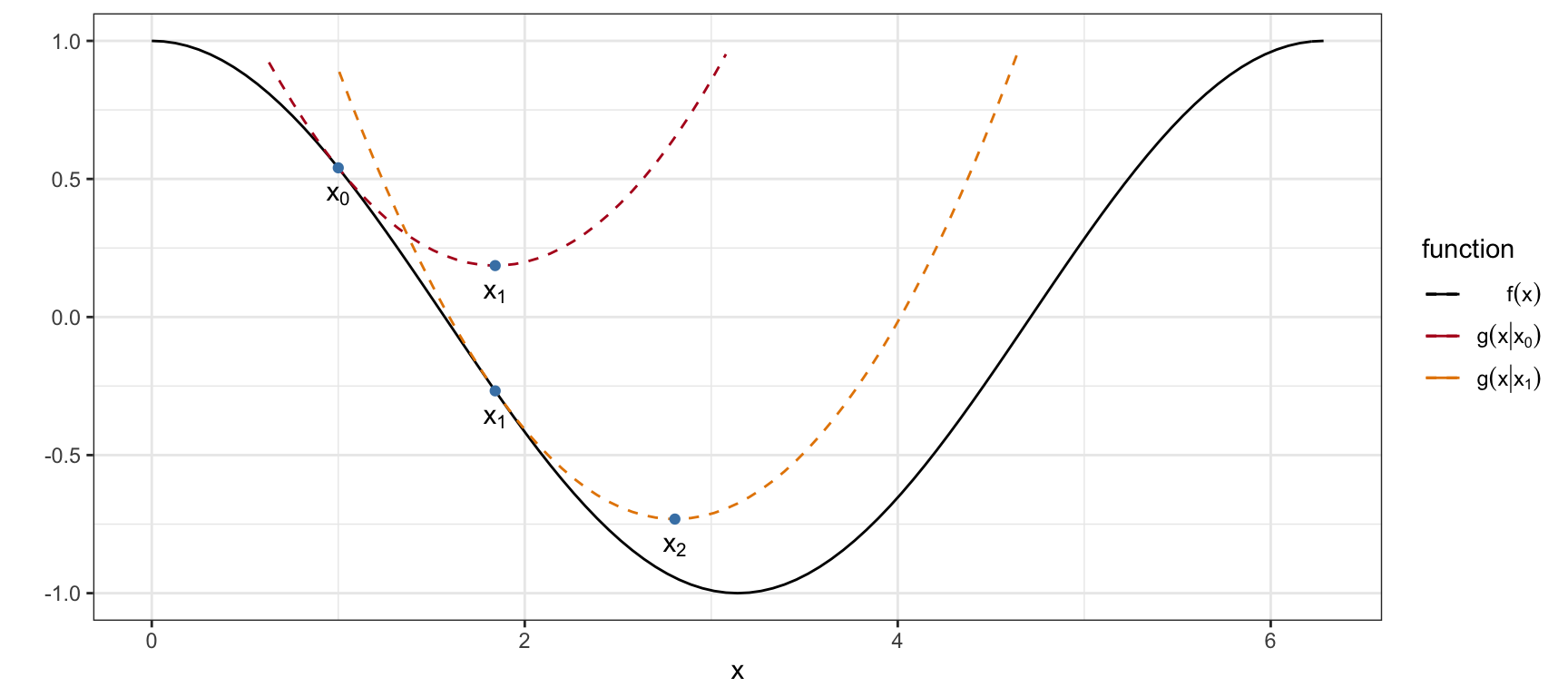
Toy (conceptual) example
We wish to minimize \(f(x) = cos(x)\).
We need a surrogate \(g\) that majorizes \(f\).
\[ g(x | x_n) = cos(x_n) - sin(x_n)(x - x_n) + \frac{1}{2}(x - x_n)^2 \]
We can minimize \(g\) easily, \(\frac{d}{dx}g(x | x_n) = -sin(x_n) + (x - x_n)\).
Next, set equal to zero and set \(x_{n+1} = x\), \(x_{n+1} = x_n + sin(x_n)\).
Convex functions
- A twice-differentiable function is convex iff \(f''(x) \geq 0\). Common examples include \(f(x) = x^2\), \(f(x) = e^x\) and \(f(x) = -\ln(x)\).
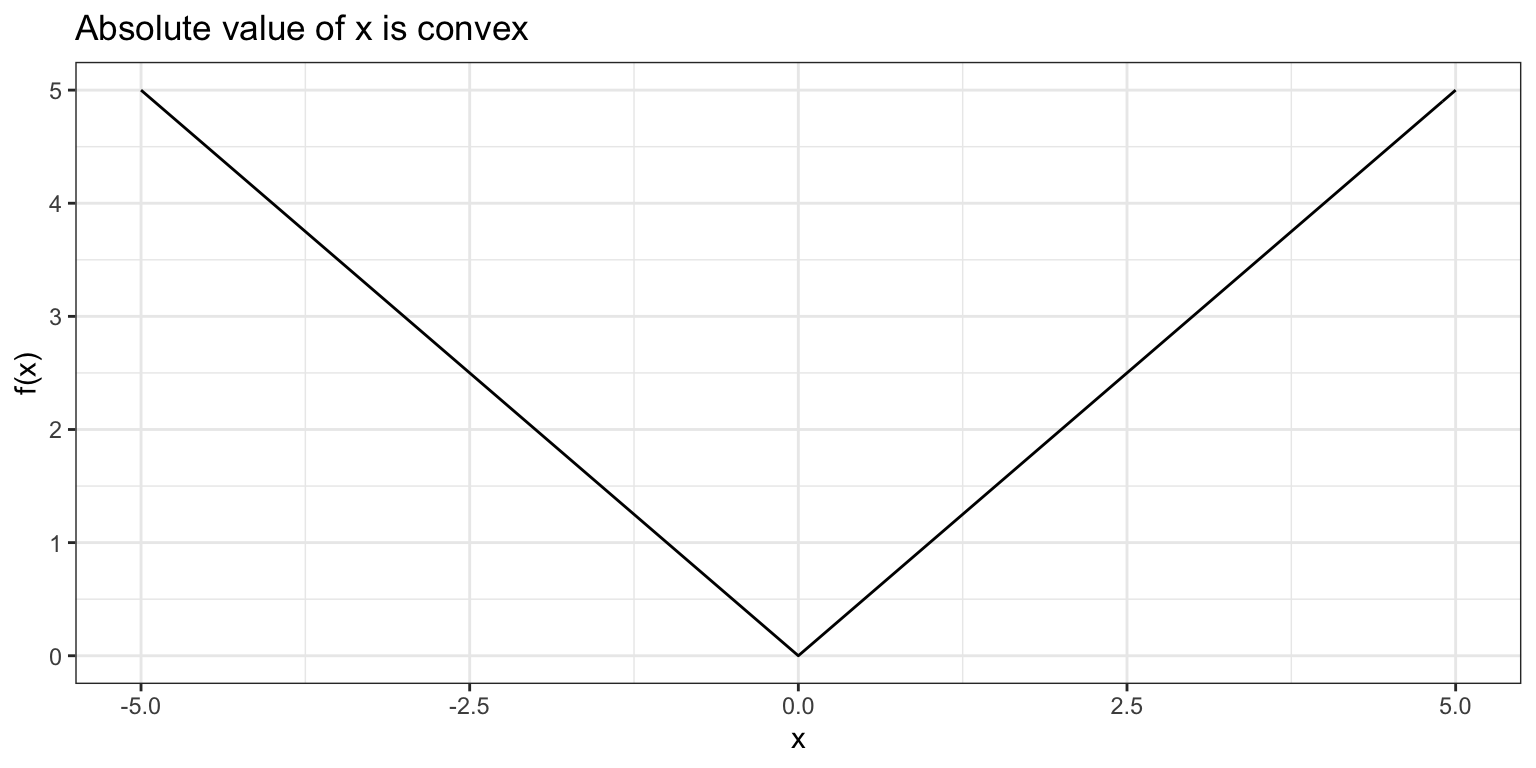
Equivalently, a function is convex if its epigraph (the points in the region above the graph of the function) form a convex set. For example, \(f(x) = |x|\) is convex by the epigraph test.
A function is concave iff its negative is convex.
Supporting line minorization
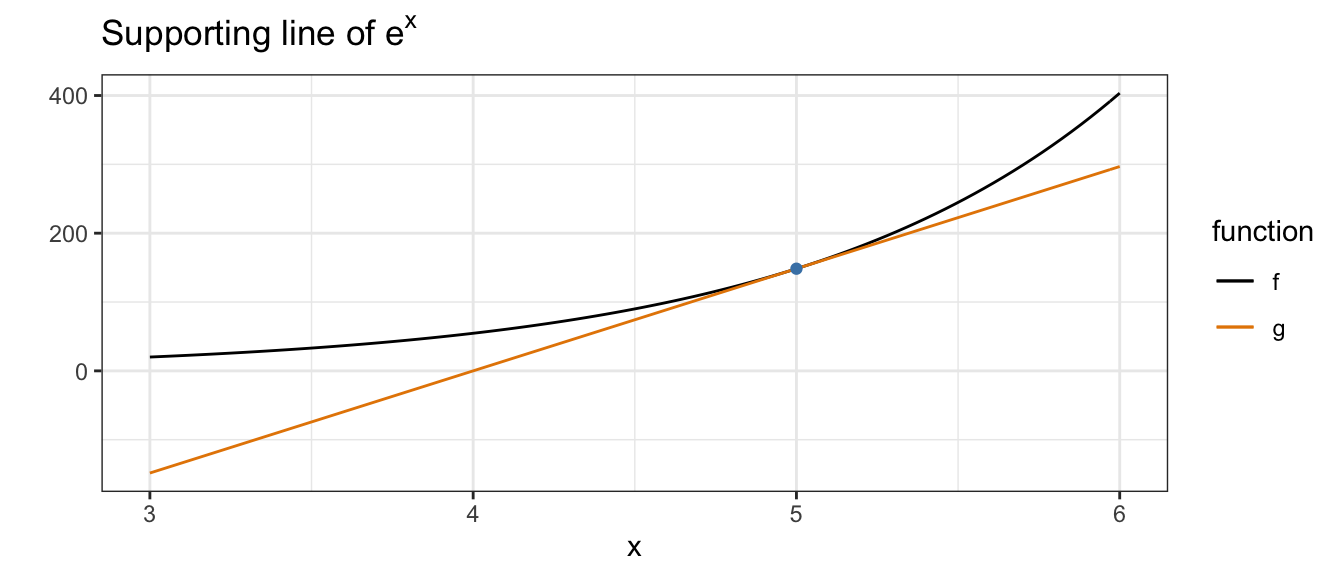
\(f(x) \geq f(x_n) + f'(x_n) (x - x_n)\) because \(f''(x_n) \geq 0\)
Check your understanding
- Write the equation of the line in this example
Jensen’s inequality
For a convex function \(f\), Jensen’s inequality states
\[ f(\alpha x + (1 - \alpha) y) \leq \alpha f(x) + (1-\alpha) f(y), \ \ \alpha \in [0, 1] \]
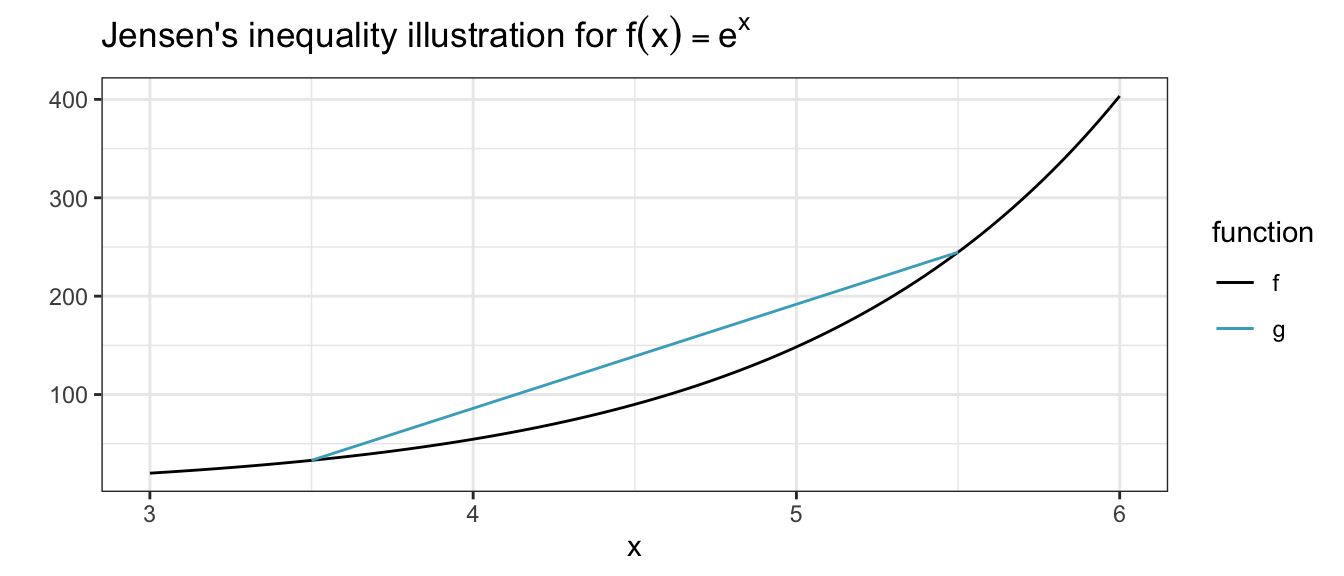
- Big use: majorizing functions of the form \(f(u(x) + v(x))\) where \(u\) and \(v\) are positive functions of parameter \(x\).
\[ f(u + v) \leq \frac{u_n}{u_n + v_n} f\left(\frac{u_n + v_n}{u_n} u\right) + \frac{v_n}{u_n + v_n} f\left(\frac{u_n + v_n}{v_n}v\right) \]