Monte Carlo integration
Duke University
The picture to have in mind
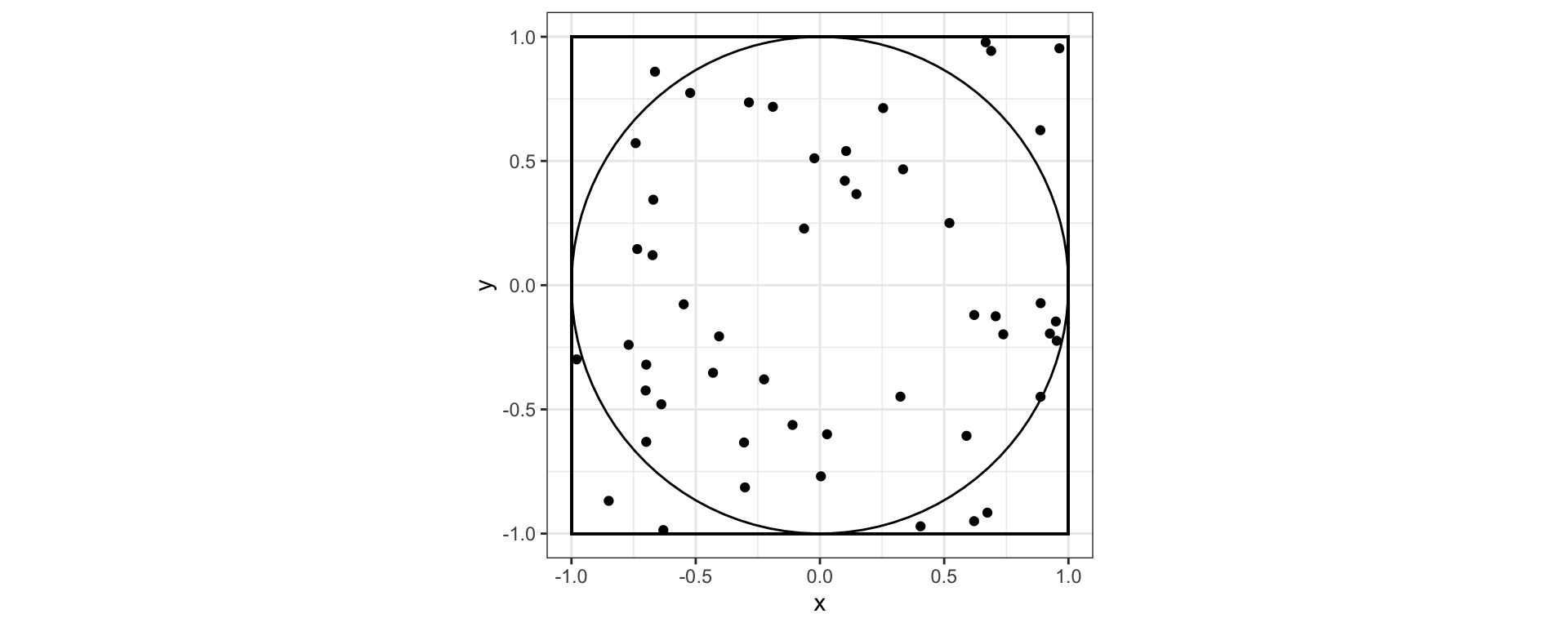
The area of the unit circle, \(A_\text{circle} = \pi\). We’ll pretend we don’t know and want to estimate \(A_\text{circle}\)
50 random points thrown into the box defined by coordinates (-1, -1), (-1, 1), (1, -1), (1, 1)
39 points land inside, 11 points outside
\(\frac{39}{50} \approx \frac{A_\text{circle}}{A_\text{box}}\)
\(A_{\text{circle}} \approx .78 \cdot 4 = 3.12\)
The curse (blessing) of dimensionality ![]()
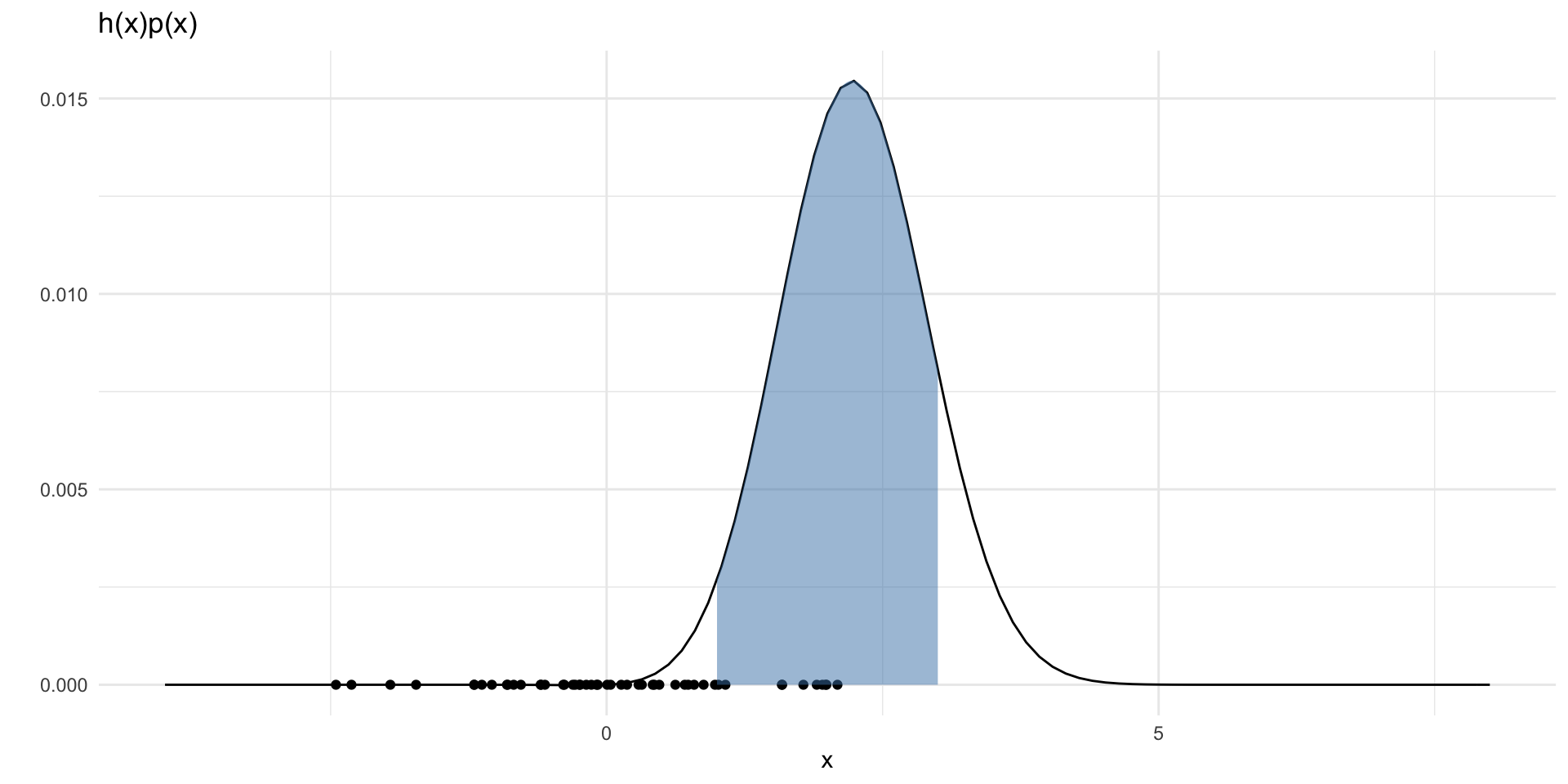
\(p(x)\) off from \(h(x)\)
- Note: here \(h(x) = x~e^{-\frac{(x-4)^2}{2}} \frac{1}{\sqrt{2\pi}}\) (i.e. I am dropping the indicator function for illustrative purposes)
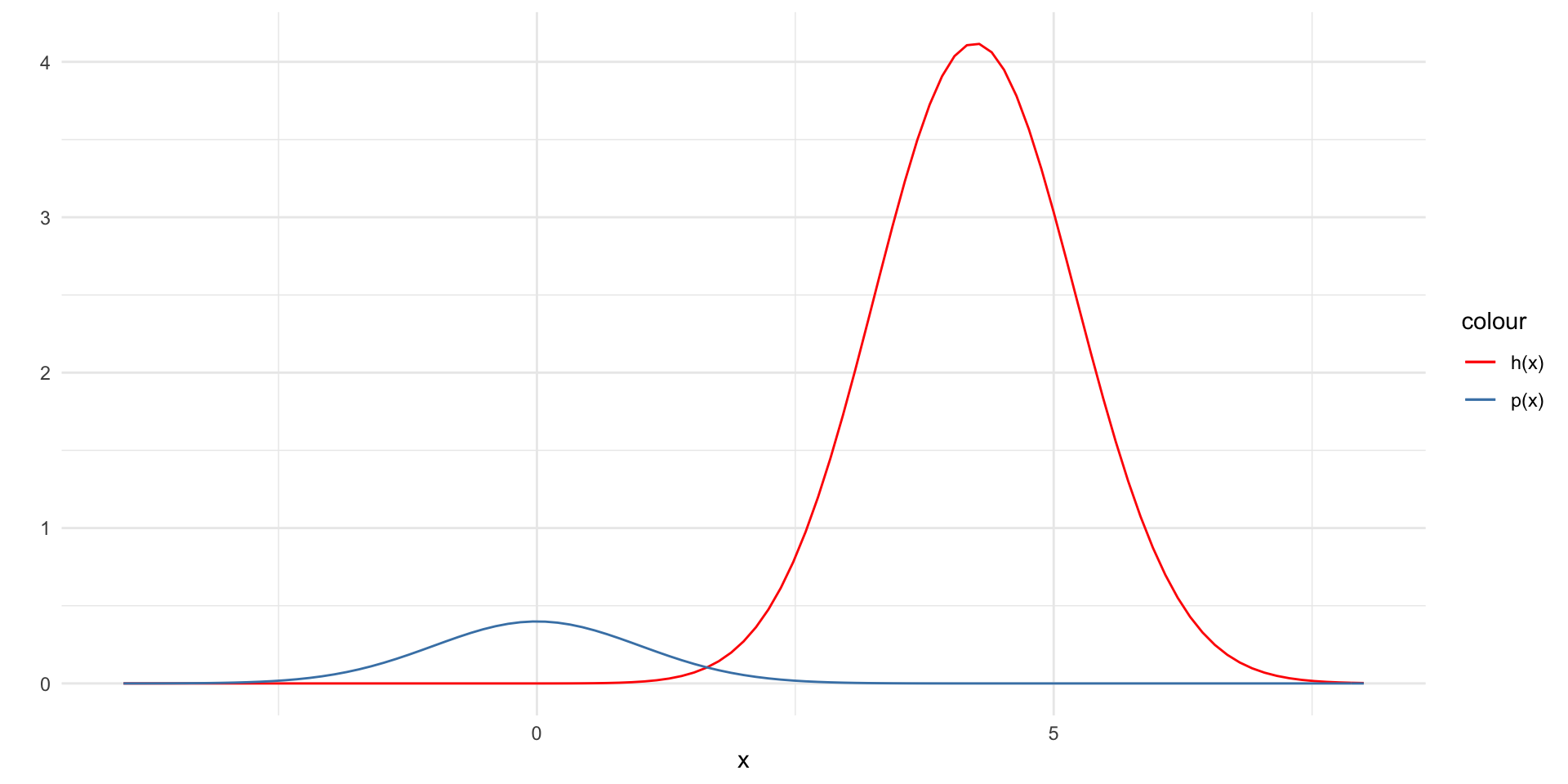
Resulting in large approximation error
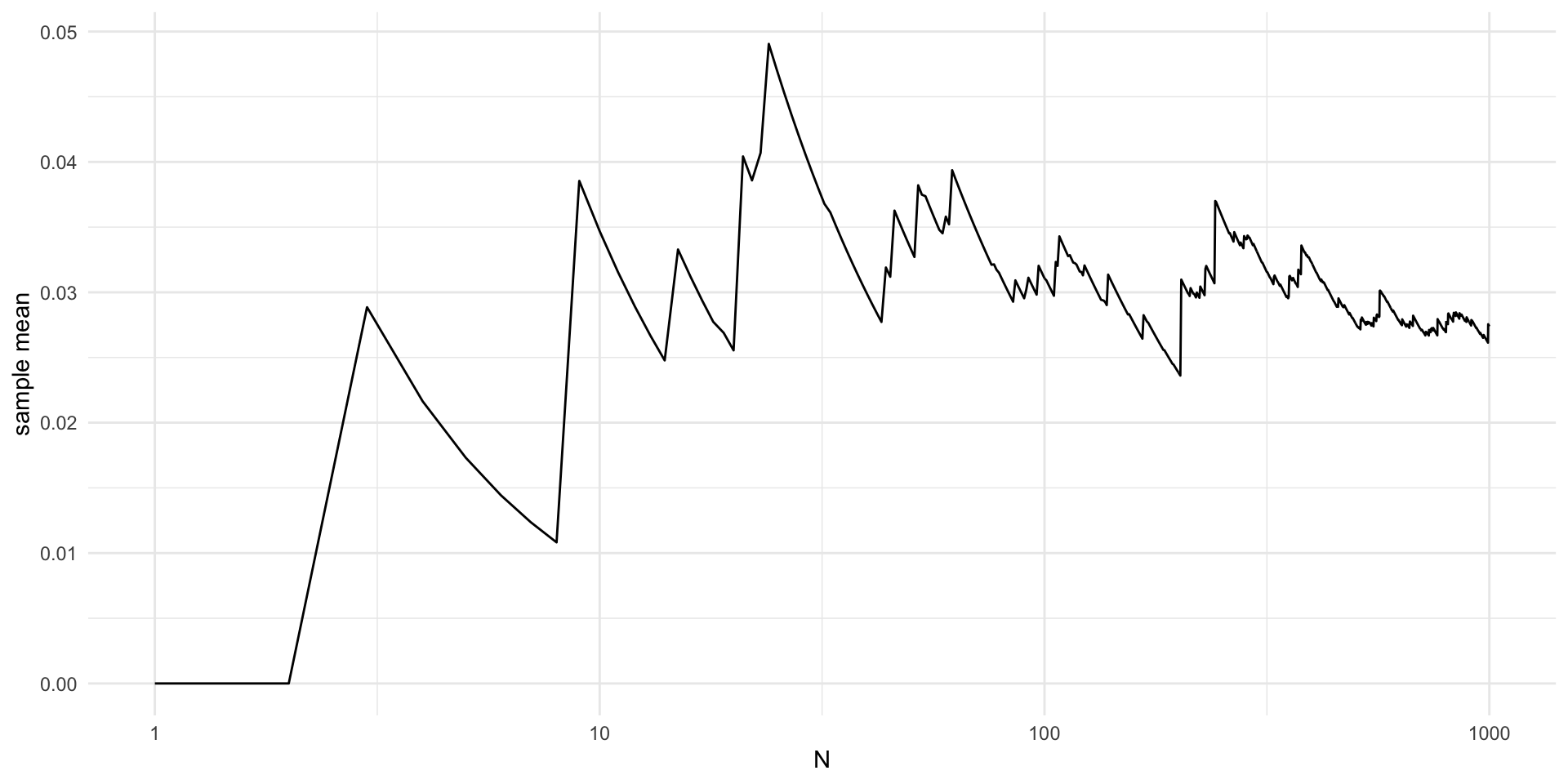
library(magrittr)
set.seed(2)
N = 1000
x = rnorm(N, 0, 1)
h1 = function(x) {
z = h(x)
z[x < 1] = 0
z[x > 3] = 0
return(z)
}
estimate = vector(length = N)
for (n in 1:N) {
estimate[n] = mean(h1(x[1:n]))
}
V = data.frame(x = seq(N),
y = estimate)
V %>%
ggplot(aes(x = x, y = y)) +
geom_line() +
theme_minimal() +
labs(x = "N", y = "sample mean") +
scale_x_continuous(trans='log10')