Covariance and Principal Components
Duke University
Visualizing covariance
Let’s look at hawk weight and wing length.
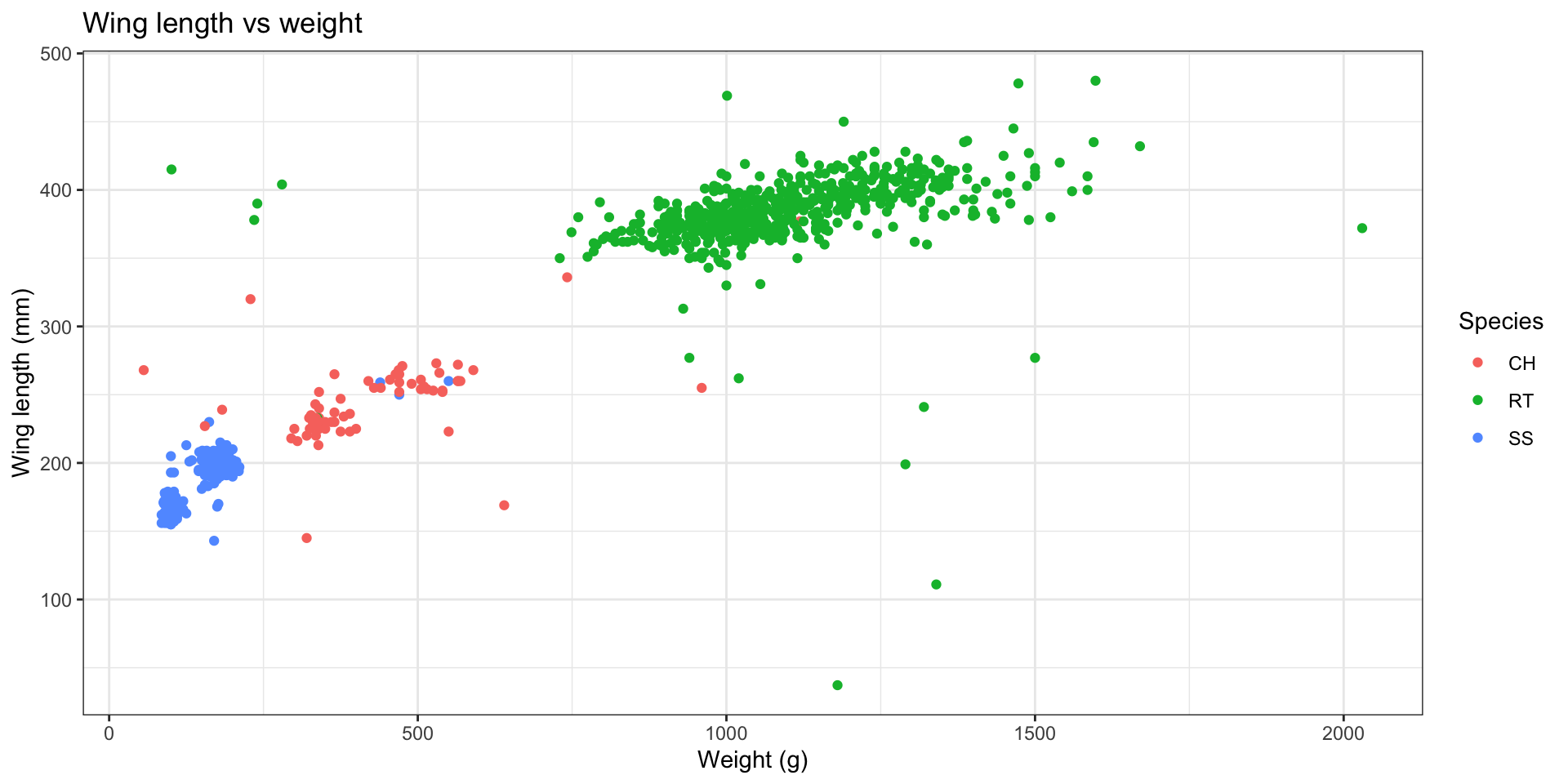
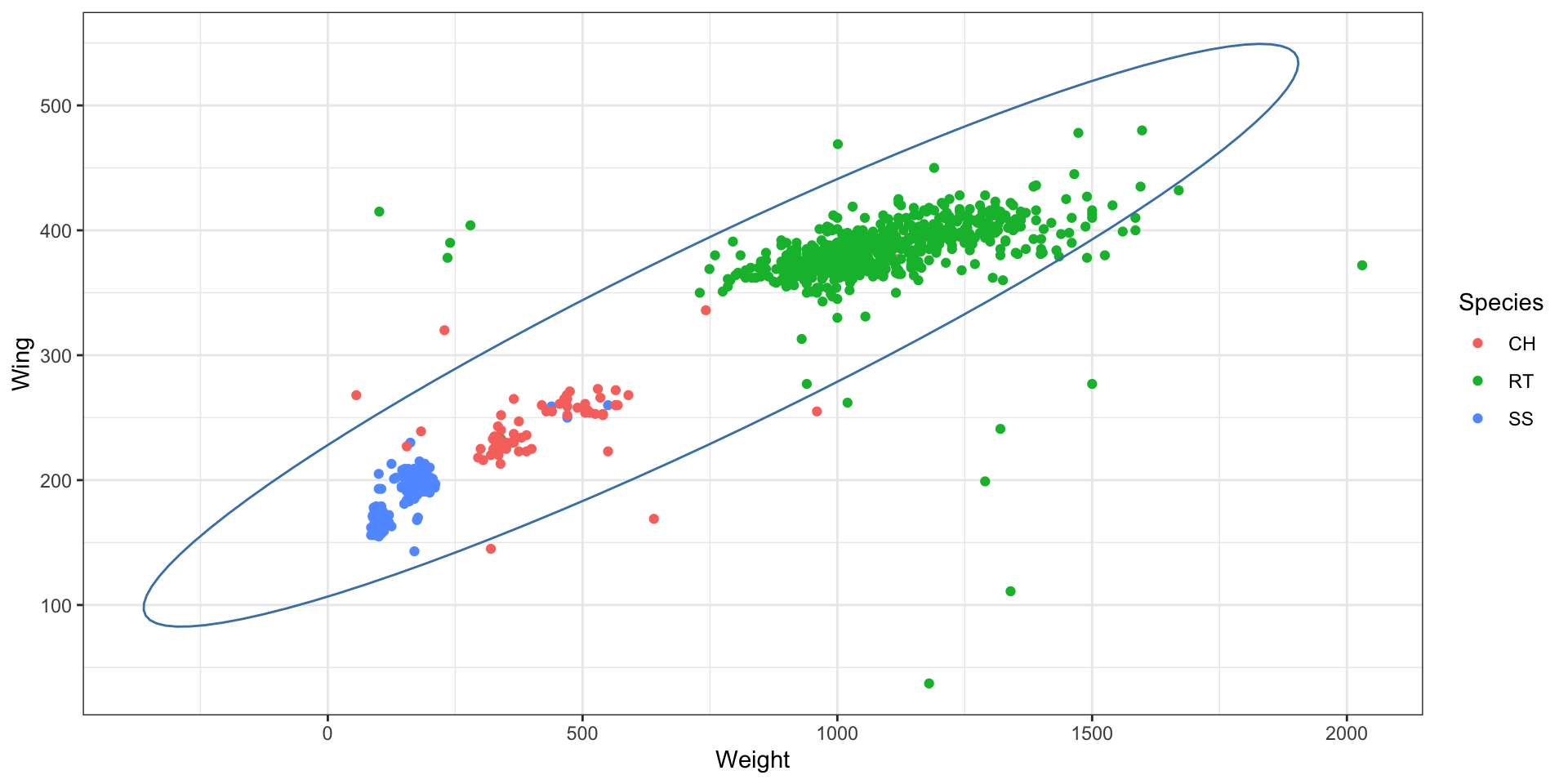
Connection: MVN
library(mvtnorm)
set.seed(1)
mu = c(5, 10)
sigma = matrix(data = c(2, .8, .8, 1), ncol = 2, nrow = 2)
points = rmvnorm(n = 500,
mean = mu,
sigma = sigma)
d = tibble(x = points[,1],
y = points[,2])
d %>%
head(n = 5)# A tibble: 5 × 2
x y
<dbl> <dbl>
1 4.20 9.96
2 4.41 11.2
3 5.17 9.34
4 5.92 10.9
5 5.68 9.91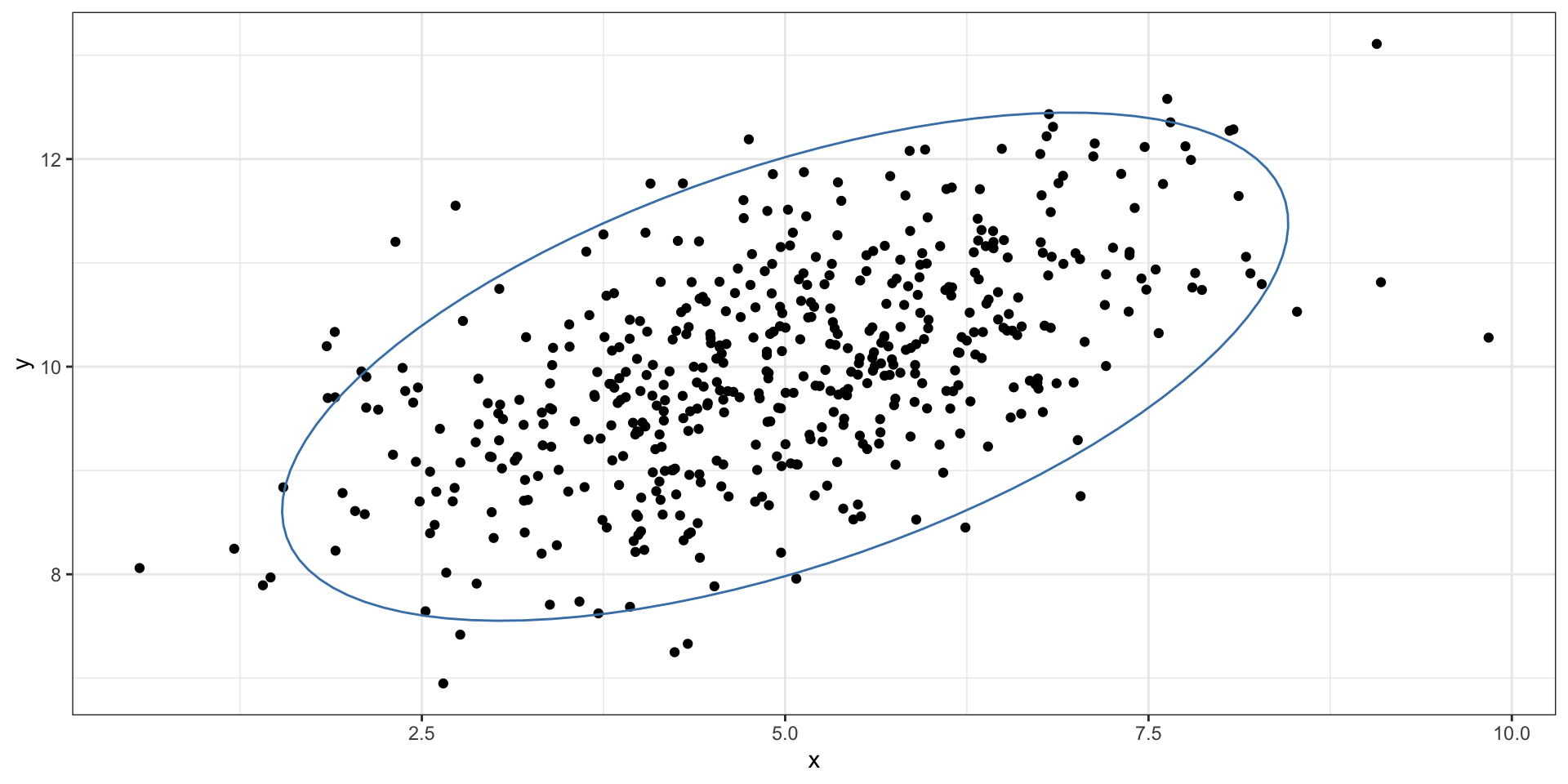
What \(c\) was used?
?ellipse has the answer… \(c^2 \approx 6\) for 2-d variables.
Exercise
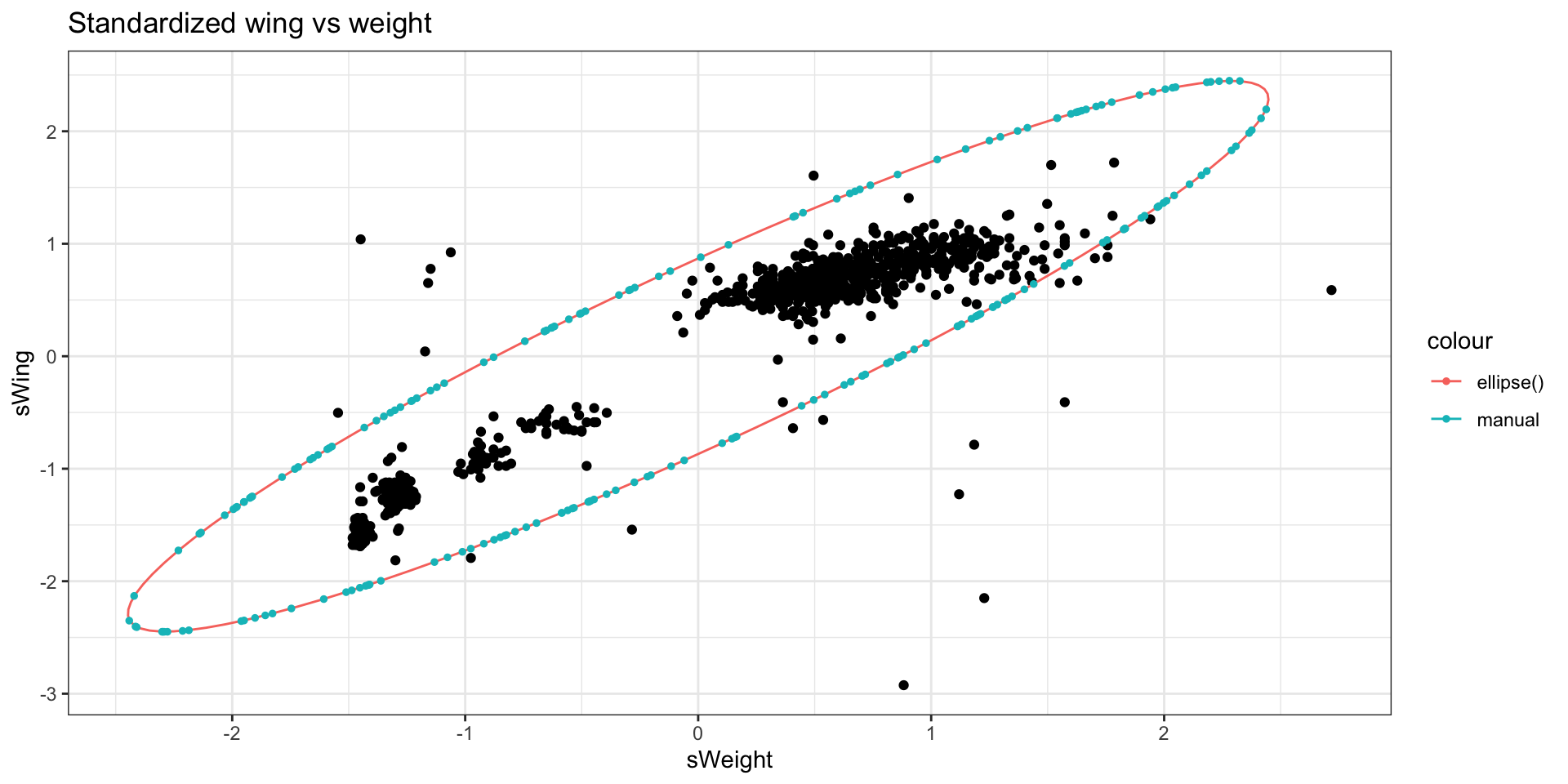
Perform a sanity check. Plot the ellipse manually using the formula from a previous slide and using \(c^2\) = 6. To avoid having to re-center on the centroid, you can standardize the data.
Hawks2 = Hawks %>%
mutate(sWeight = (Weight - mean(Weight)) / sd(Weight),
sWing = (Wing - mean(Wing)) / sd(Wing))
covMatrix2 = Hawks2 %>%
select(sWeight, sWing) %>%
cov()
covMatrix2 sWeight sWing
sWeight 1.0000000 0.9347852
sWing 0.9347852 1.0000000Next, get \(\Sigma^{-1}\):
Next, we manually solve the quadratic equation using the quadratic formula (set \(c^2 = 6\))
\[ x^2 s_x^2 + 2x y \cdot s_{xy}^2 + y^2 s_y^2 = 6 \]
set.seed(1)
# Grab the points (x,y) that satisfy the equation
ellipsePoints = data.frame(ellipse(covMatrix2))
m1 = data.frame(x = seq(-3, 3, by = 0.001)) %>%
mutate(y = f(x)) %>%
filter(!is.nan(y))
m2 = m1 %>%
mutate(y = f2(x)) %>%
filter(!is.nan(y))
manualEllipsePoints = rbind(m1, m2) %>%
slice_sample(n = 200)
Hawks2 %>%
ggplot(aes(x = sWeight, y = sWing)) +
geom_point() +
theme_bw() +
geom_path(aes(x = sWeight, y = sWing,
color = "ellipse()"), data = ellipsePoints) +
geom_point(aes(x = x, y = y, color = "manual"),
data = manualEllipsePoints, alpha = 1,
size = 1,) +
labs(title = "Standardized wing vs weight")Principal components
The axes of the ellipse provide the most informative directions to measure the data. In \(n\)-dimensions, where we have a \(n\)-dimensional ellipsoid, it can be useful to look at \(p<n\) axes. The largest axis is called the “first” principal component. The second largest axis is called the “second” principal component and so on.
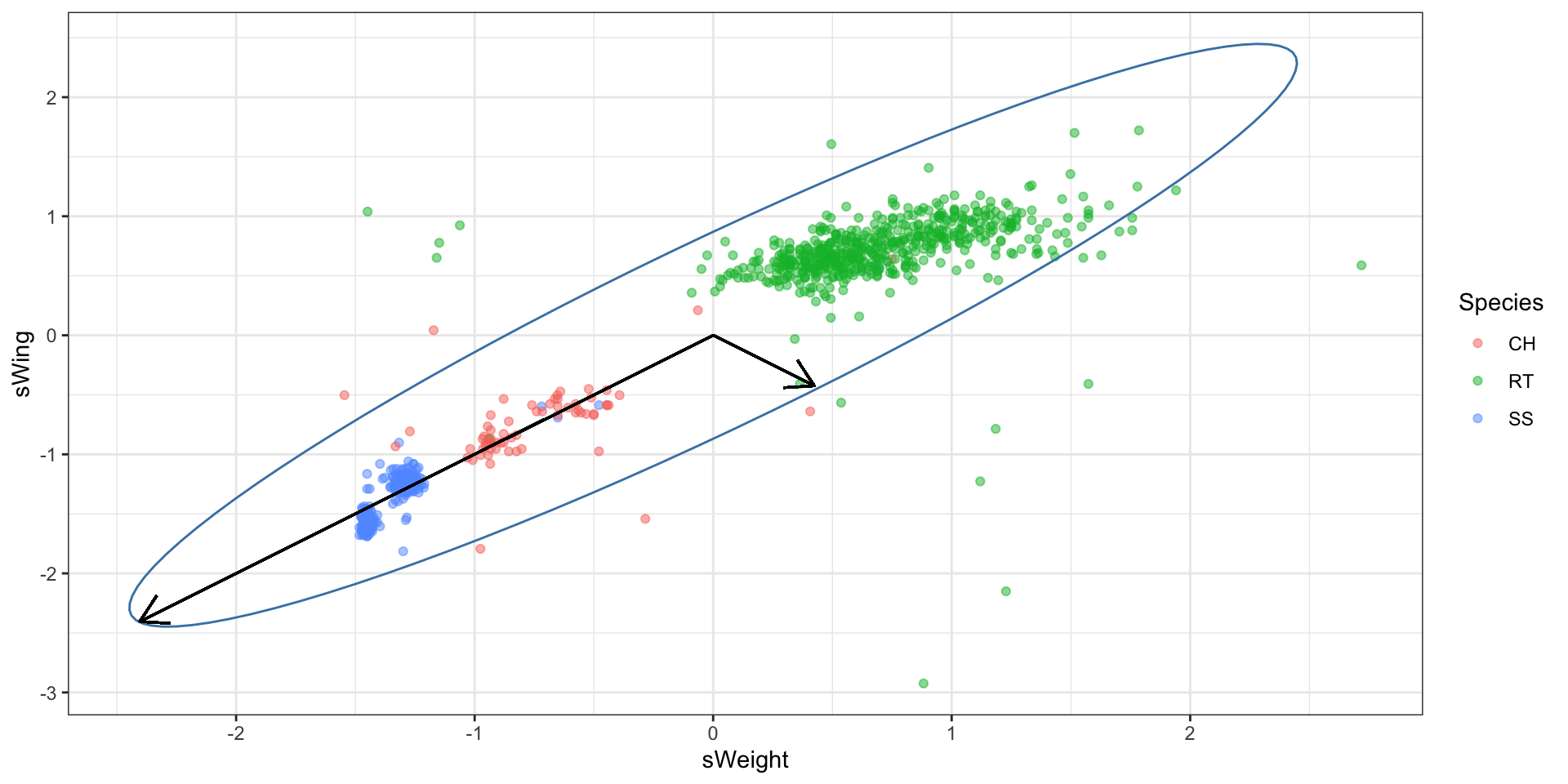
Compute principal components
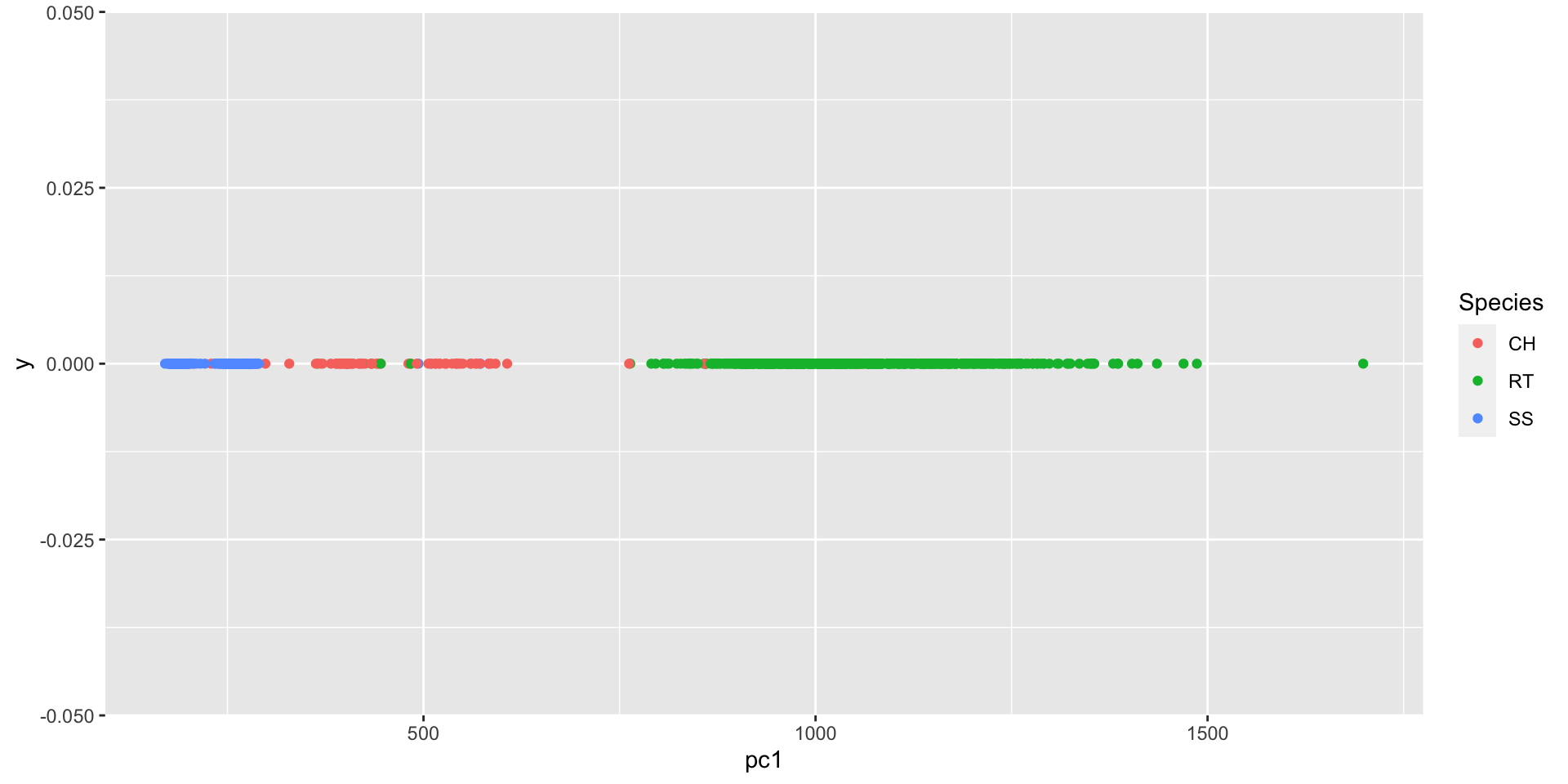
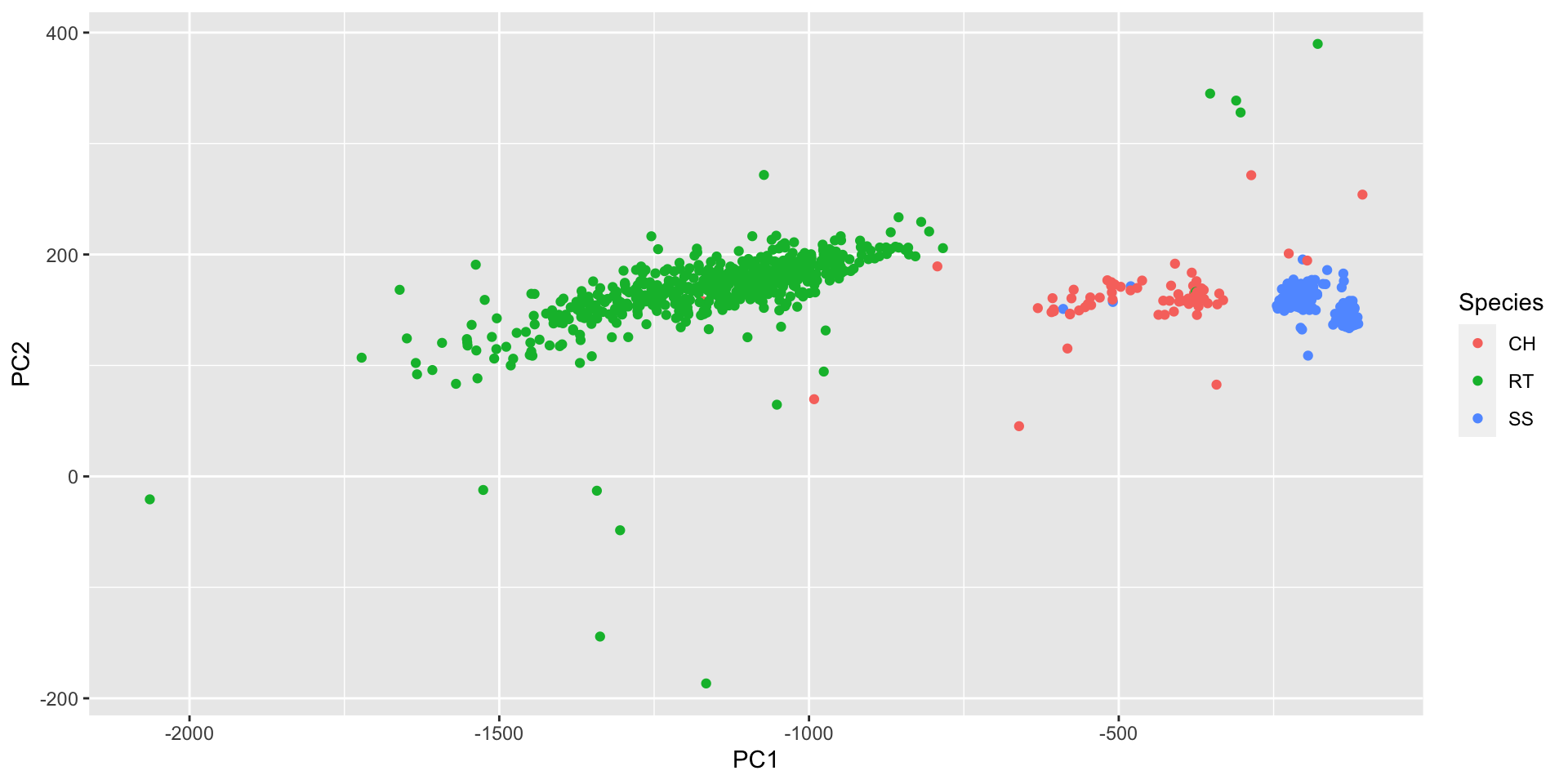
Higher dimensional example
hpc = Hawks %>%
select(Weight, Wing, Culmen, Hallux) %>%
prcomp(scale = FALSE) %>%
.["rotation"] %>%
as.data.frame() %>%
setNames(., paste0("PC", seq(4)))
# explicitly mapping
Hawks %>%
mutate(PC1 = (hpc$PC1[1] * Weight) +
(hpc$PC1[2] * Wing) +
(hpc$PC1[3] * Culmen) +
(hpc$PC1[4] * Hallux),
PC2 = (hpc$PC2[1] * Weight) +
(hpc$PC2[2] * Wing) +
(hpc$PC2[3] * Culmen) +
(hpc$PC2[4] * Hallux)) %>%
ggplot(aes(x = PC1, y = PC2, color = Species)) +
geom_point()